It is a relatively rare event, and cause for celebration, when CRAN gets a new Task View. This week the r-miss-tastic team: Julie Josse, Nicholas Tierney and Nathalie Vialaneix launched the Missing Data Task View. Even though I did some research on R packages for a post on missing values a couple of years ago, I was dumbfounded by the number of packages included in the new Task View.
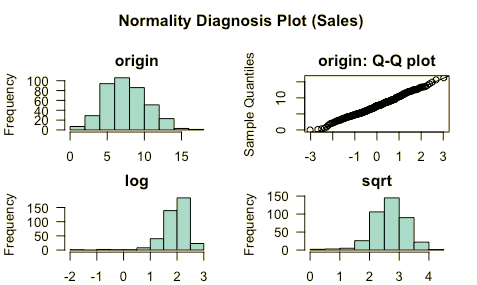
This single page not only describes what R has to offer with respect to coping with missing data, it is probably the world’s most complete index of statistical knowledge on the subject. But, the task view is not just devoted to esoterica. The Exploration of missing data section contains a number of tools that should be useful in any data wrangling effort like this plot diagnostic plot from the dlookr package.
The downside that may curb one’s enthusiasm, is that mastering missing data techniques requires some serious study. Missing data problems are among the most vexing in statistics, and the newer techniques for tackling these problems are relatively sophisticated. So, unless you are a na.omit() kind of guy/gal (a data scientist?) coming to grips with NAs may involve a subtle inferential task embedded in the usual data wrangling effort.
It is also the case that it is not easy to find good introductory material on the subject. The notable exception is Stef van Buuren’s authoritative R-based textbook, Flexible Imputation of Missing Data which he has graciously made available online.
I also found the review papers by Dong and Peng and by Horton and Kleinman to be helpful. And, if you read French a little better than I do, the review by Imbert and Vialaneix looks like it covers all of the basic material.
Finally, I should mention that the Missing Data Task View is part of the R Consortium funded project A unified platform for missing values methods and workflows. Many thanks to the ISC for making it possible for the expert r-miss-tastic team to do the work.
You may leave a comment below or discuss the post in the forum community.rstudio.com.