One hundred and thirteen new packages made it to CRAN in September. Here are my “Top 40” picks in eight categories: Computational Methods, Data, Economics, Machine Learning, Statistics, Time Series, Utilities, and Visualization.
Computational Methods
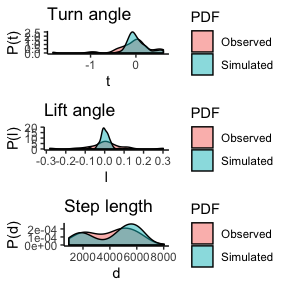
eRTG3D v0.6.2: Provides functions to create realistic random trajectories in a 3-D space between two given fixed points (conditional empirical random walks), based on empirical distribution functions extracted from observed trajectories (training data), and thus reflect the geometrical movement characteristics of the mover. There are several small vignettes, including sample data sets, linkage to the sf package, and point cloud analysis.
freealg v1.0: Implements the free algebra in R: multivariate polynomials with non-commuting indeterminates. See the vignette for the math.
HypergeoMat v3.0.0: Implements Koev & Edelman’s algorithm (2006) to evaluate the hypergeometric functions of a matrix argument, which appear in random matrix theory. There is a vignette.
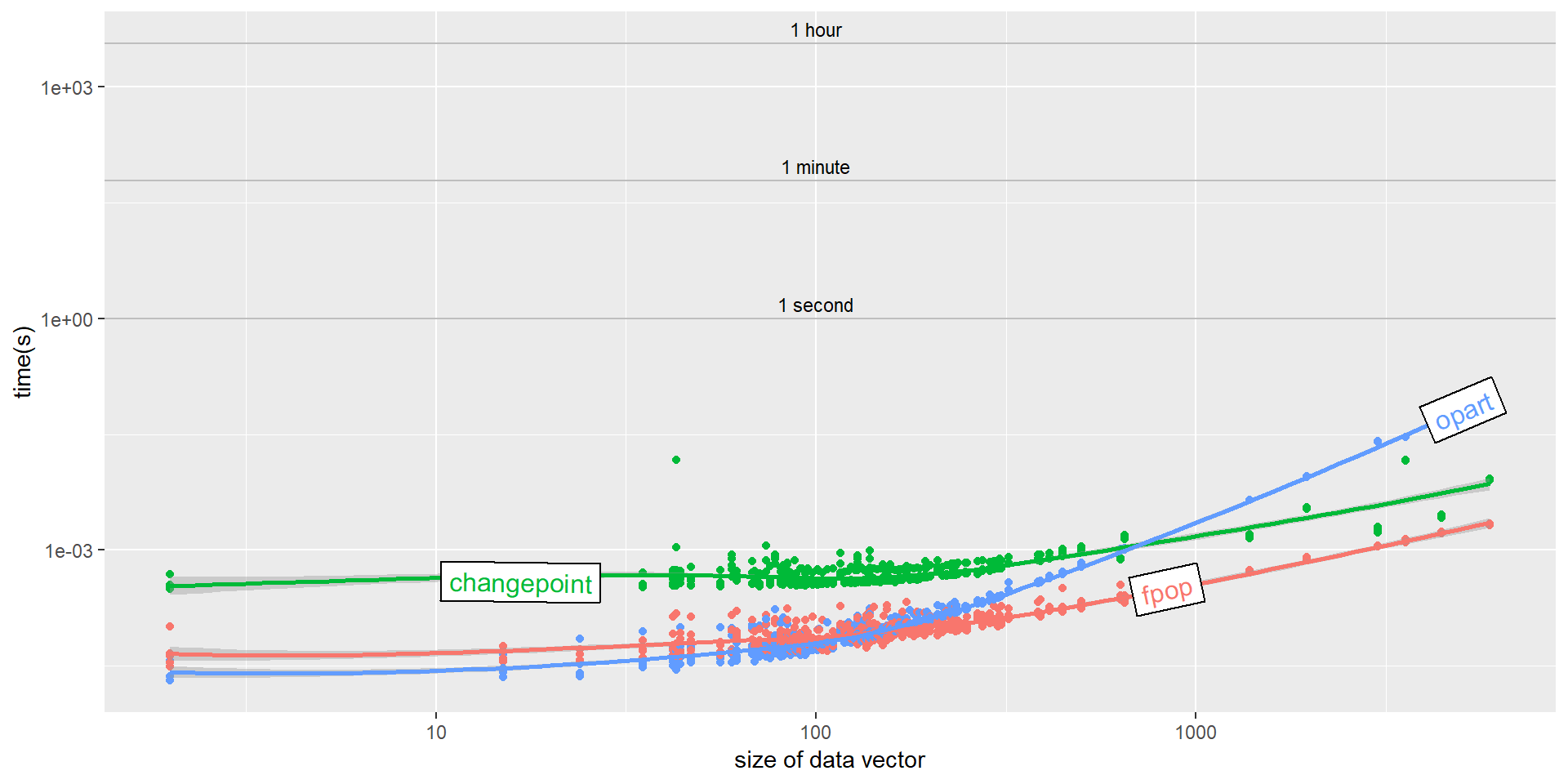
opart v2019.1.0: Provides a reference implementation of standard optimal partitioning algorithm in C using square-error loss and Poisson loss functions as described by Maidstone (2016), Hocking (2016), Rigaill (2016), and Fearnhead (2016) that scales quadratically with the number of data points in terms of time-complexity. There are vignettes for Gaussian and Poisson squared error loss.
Data
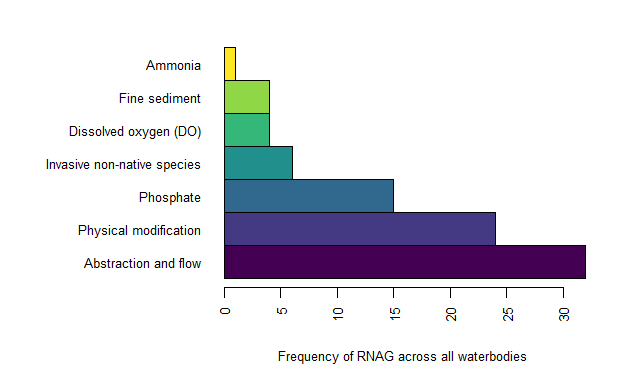
cde v0.4.1: Facilitates searching, download and plotting of Water Framework Directive (WFD) reporting data for all water bodies within the UK Environment Agency area. This package has been peer-reviewed by rOpenSci. There is a Getting Started Guide and a vignette on output reference.
eph v0.1.1: Provides tools to download and manipulate data from the Argentina Permanent Household Survey. The implemented methods are based on INDEC (2016).
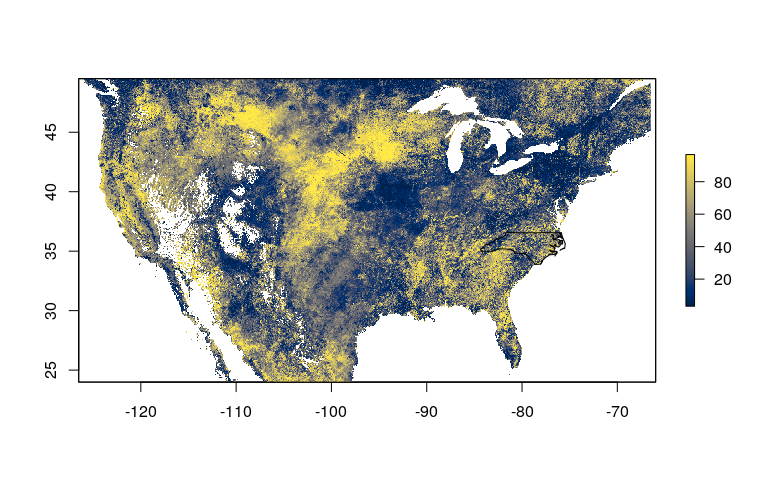
leri v0.0.1: Fetches Landscape Evaporative Response Index (LERI) data using the raster package. The LERI product measures anomalies in actual evapotranspiration, to support drought monitoring and early warning systems. See the vignette for examples.
rwhatsapp v0.2.0: Provides functions to parse and digest history files from the popular messenger service WhatsApp. There is a vignette.
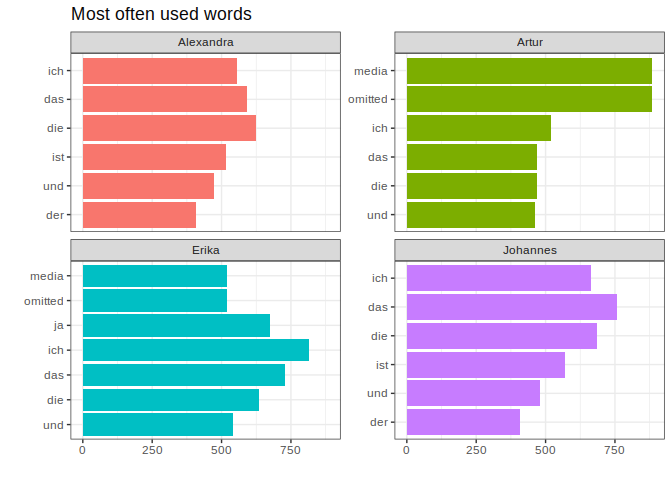
tidyUSDA v0.2.1: Provides a consistent API to pull United States Department of Agriculture census and survey data from the National Agricultural Statistics Service (NASS) QuickStats service. See the vignette.
Economics
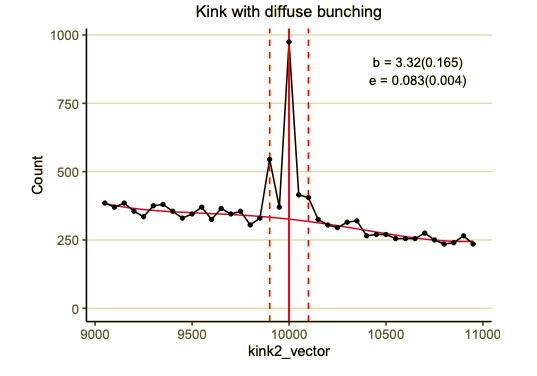
bunching v0.8.4: Implements the bunching estimator from economic theory for kinks and knots. There is a vignette on Theory, and another with Examples.
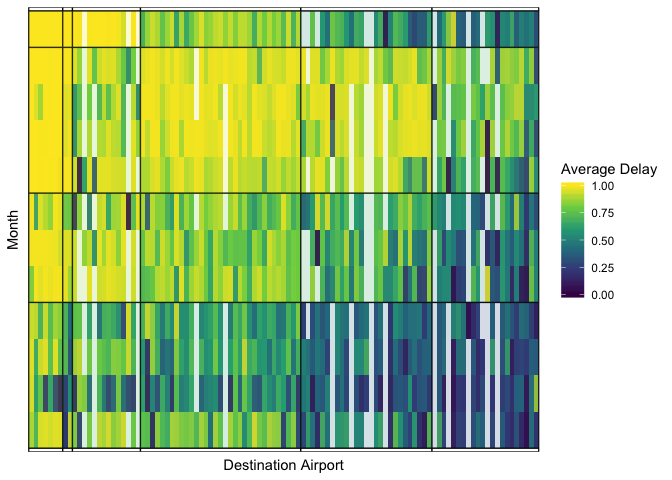
fixest v0.1.2: Provides fast estimation of econometric models with multiple fixed-effects, including ordinary least squares (OLS), generalized linear models (GLM), and the negative binomial. The method to obtain the fixed-effects coefficients is based on Berge (2018). There is a vignette.
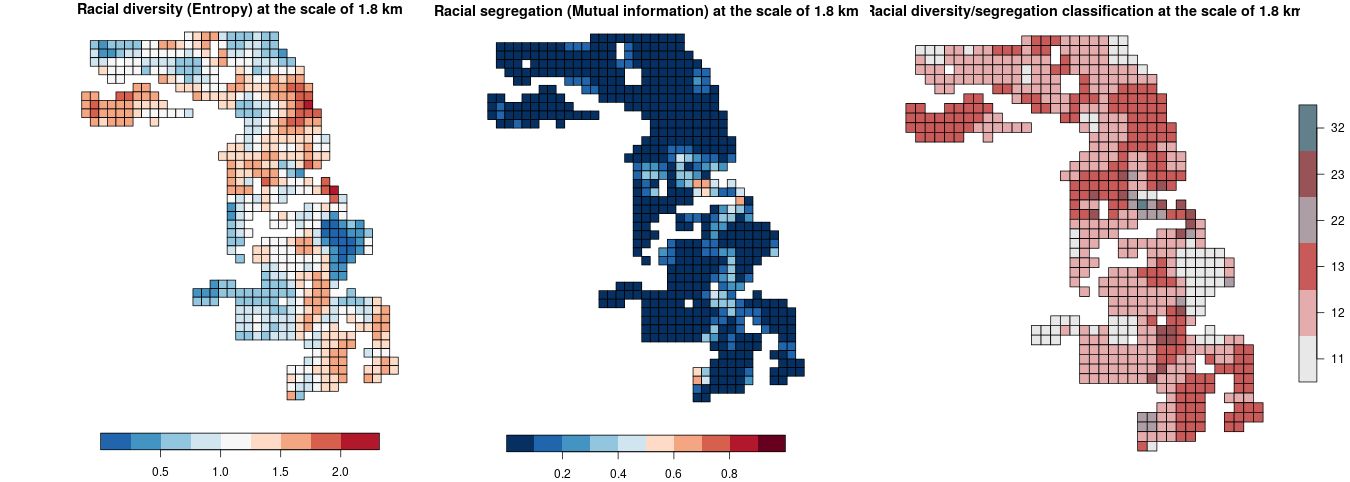
raceland v1.0.3: Implements a computational framework for a pattern-based, zoneless analysis, and visualization of (ethno)racial topography for analyzing residential segregation and racial diversity. There is a vignette describing the Computational Framework, one describing Patterns of Racial Landscapes, and a third on SocScape Grids.
Machine Learning
biclustermd v0.1.0: Implements biclustering, a statistical learning technique that simultaneously partitions, and clusters rows and columns of a data matrix in a manner that can deal with missing values. See the vignette for examples.
bbl v0.1.5: Implements supervised learning using Boltzmann Bayes model inference, enabling the classification of data into multiple response groups based on a large number of discrete predictors that can take factor values of heterogeneous levels. See Woo et al. (2016) for background, and the vignette for how to use the package.
corporaexplorer v0.6.3: Implements Shiny apps to dynamically explore collections of texts. Look here for more information.
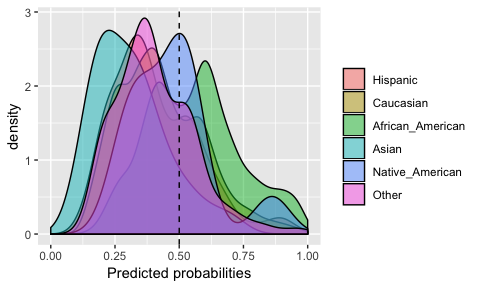
fairness v1.0.1: Offers various metrics to assess and visualize the algorithmic fairness of predictive and classification models using methods described by Calders and Verwer (2010), Chouldechova (2017), Feldman et al. (2015), Friedler et al. (2018), and Zafar et al. (2017). There is a tutorial for the package.
imagefluency v0.2.1: Provides functions to collect image statistics based on processing fluency theory that include scores for several basic aesthetic principles that facilitate fluent cognitive processing of images: contrast, complexity / simplicity, self-similarity, symmetry, and typicality. See Mayer & Landwehr (2018) and Mayer & Landwehr (2018) for the theoretical background, and the vignette for an introduction.

ineqJD v1.0: Provides functions to compute and decompose Gini, Bonferroni, and Zenga 2007 point and synthetic concentration indexes. See Zenga M. (2015), Zenga & Valli (2017), and Zenga & Valli (2018) for more information.
lmds v0.1.0: Implements Landmark Multi-Dimensional Scaling (LMDS), a dimensionality reduction method scaleable to large numbers of samples, because rather than calculating a complete distance matrix between all pairs of samples, it only calculates the distances between a set of landmarks and the samples. See the README for an example.
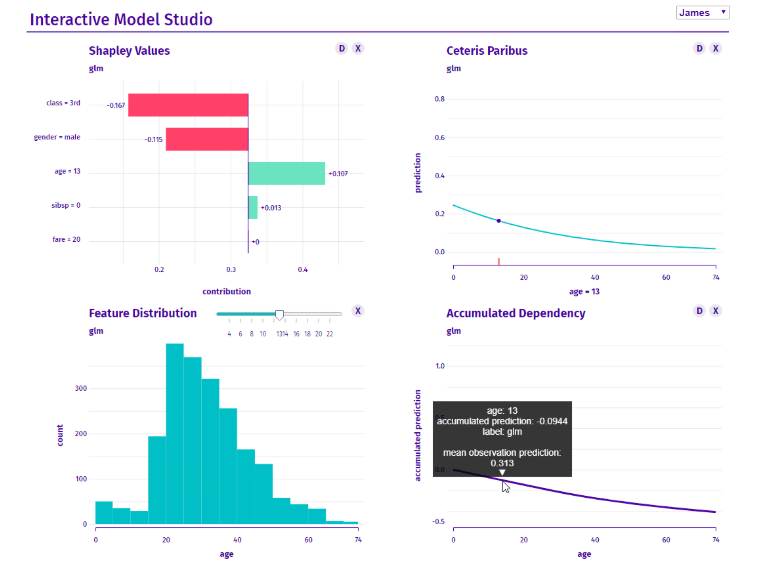
modelStudio v0.1.7: Implements an interactive platform to help interpret machine learning models. There is a vignette, and look here for a demo of the interactive features.
nlpred v1.0: Provides methods for obtaining improved estimates of non-linear cross-validated risks obtained using targeted minimum loss-based estimation, estimating equations, and one-step estimation. Cross-validated area under the receiver operating characteristics curve ( LeDell sr al. (2015) ) and other metrics are included. There is a vignette on small sample estimates.
pyMTurkR v1.1: Provides access to the latest Amazon Mechanical Turk’ (‘MTurk’) Requester API (version ‘2017–01–17’), replacing the now deprecated MTurkR package.
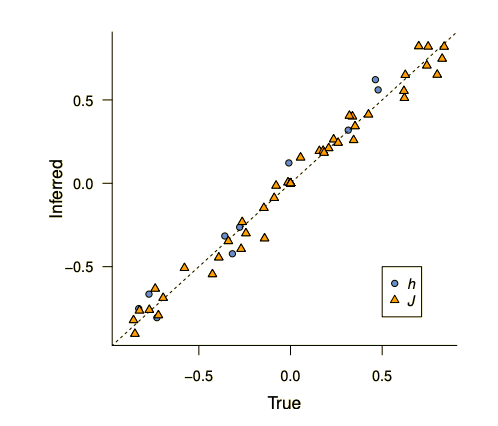
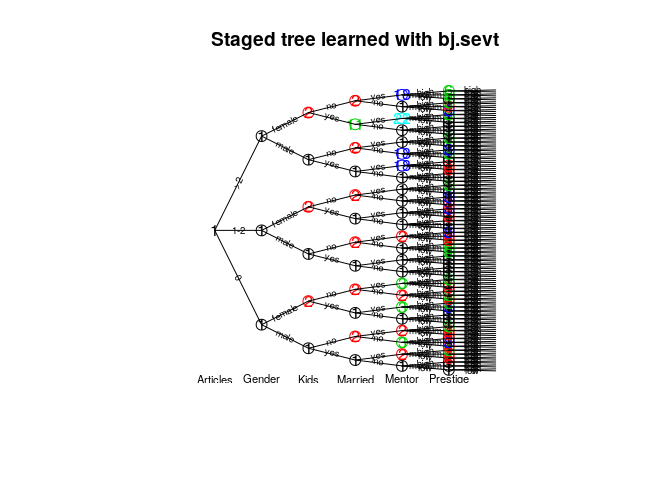
stagedtrees v1.0.0: Creates and fits staged event tree probability models, probabilistic graphical models capable of representing asymmetric conditional independence statements among categorical variables. See Görgen et al. (2018), Thwaites & Smith (2017), Barclay et al. (2013), and Smith & Anderson](doi:10.1016/j.artint.2007.05.004) for background, and look here for and overview.
Statistics
confoundr v1.2: Implements three covariate-balance diagnostics for time-varying confounding and selection-bias in complex longitudinal data, as described in Jackson (2016) and Jackson (2019). There is a Demo vignette and another Describing Selection Bias from Dependent Censoring
distributions3 v0.1.1: Provides tools to create and manipulate probability distributions using S3. Generics random(), pdf(), cdf(), and quantile() provide replacements for base R’s r/d/p/q style functions. The documentation for each distribution contains detailed mathematical notes. There are several vignettes: Intro to hypothesis testing, One-sample sign tests,
One-sample T confidence interval, One-sample T-tests, Z confidence interval for a mean, One-sample Z-tests for a proportion, One-sample Z-tests, Paired tests, and Two-sample Z-tests.
dobin v0.8.4: Implements a dimension reduction technique for outlier detection, which constructs a set of basis vectors for outlier detection that bring outliers to the forefront using fewer basis vectors. See Kandanaarachchi & Hyndman (2019) for background, and the vignette for a brief introduction.
glmpca v0.1.0: Implements a generalized version of principal components analysis (GLM-PCA) for dimension reduction of non-normally distributed data, such as counts or binary matrices. See Townes et al. (2019) and Townes (2019) for details, and the vignette for examples.
immuneSIM v0.8.7: Provides functions to simulate full B-cell and T-cell receptor repertoires using an in-silico recombination process that includes a wide variety of tunable parameters to introduce noise and biases. See Weber et al. (2019) for background, and look here for information about the package.
irrCAC v1.0: Provides functions to calculate various chance-corrected agreement coefficients (CAC) among two or more raters, including Cohen’s kappa, Conger’s kappa, Fleiss’ kappa, Brennan-Prediger coefficient, Gwet’s AC1/AC2 coefficients, and Krippendorff’s alpha. There are vignettes on benchmarking, Calculating Chance-corrected Agreement Coefficients, and Computing weighted agreement coefficients.
LPBlg v1.2: Provides functions that estimate a density and derive a deviance test to assess if the data distribution deviates significantly from the postulated model, given a postulated model and a set of data. See Algeri S. (2019) for details.
SynthTools v1.0.0: Provides functions to support experimentation with partially synthetic data sets. Confidence interval and standard error formulas have options for either synthetic data sets or multiple imputed data sets. For more information, see Reiter & Raghunathan (2007).
Time Series
fable v0.1.0: Provides a collection of commonly used univariate and multivariate time series forecasting models, including automatically selected exponential smoothing (ETS) and autoregressive integrated moving average (ARIMA) models. There is an Introduction and a vignette on transformations.
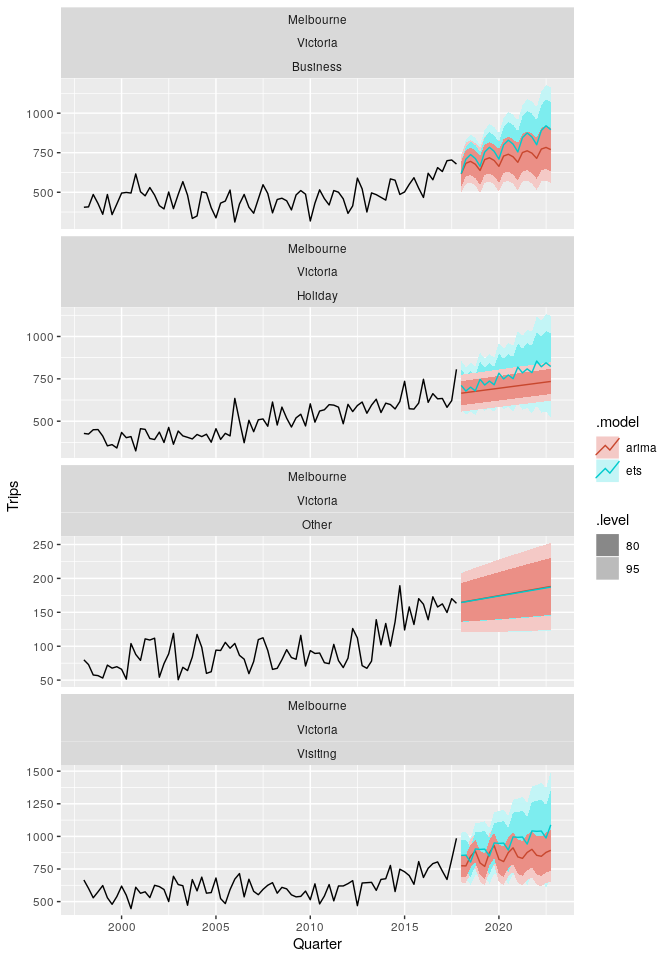
nsarfima v0.1.0.0: Provides routines for fitting and simulating data under autoregressive fractionally integrated moving average (ARFIMA) models, without the constraint of stationarity. Two fitting methods are implemented: a pseudo-maximum likelihood method and a minimum distance estimator. See Mayoral (2007) and Beran (1995) for reference.
Utilities
nc v2019.9.16: Provides functions for extracting a data table (row for each match, column for each group) from non-tabular text data using regular expressions. Patterns are defined using a readable syntax that makes it easy to build complex patterns in terms of simpler, re-usable sub-patterns. There is a vignette on capture first match and another on capture all match.
pins v0.2.0: Provides functions that “pin” remote resources into a local cache in order to work offline, improve speed, avoid recomputing, and discover and share resources in local folders, GitHub, Kaggle and RStudio Connect. There is a Getting Started Guide and vignettes on Extending Boards, Using GitHub Boards, Using Kaggle Boards, Using RStudio Connect Boards, Using Website Boards, Using Pins in RStudio, Understanding Boards, and Extending Pins.
queryparser v0.1.1: Provides functions to translate SQL SELECT statements into lists of R expressions.
rawr v0.1.0: Retrieves pure R code from popular R websites, including github, kaggle, datacamp, and R blogs made using blogdown.
Visualization
FunnelPlotR v0.2.1: Implements Spiegelhalter (2005) Funnel plots for reporting standardized ratios, with overdispersion adjustment. The vignette offers examples.

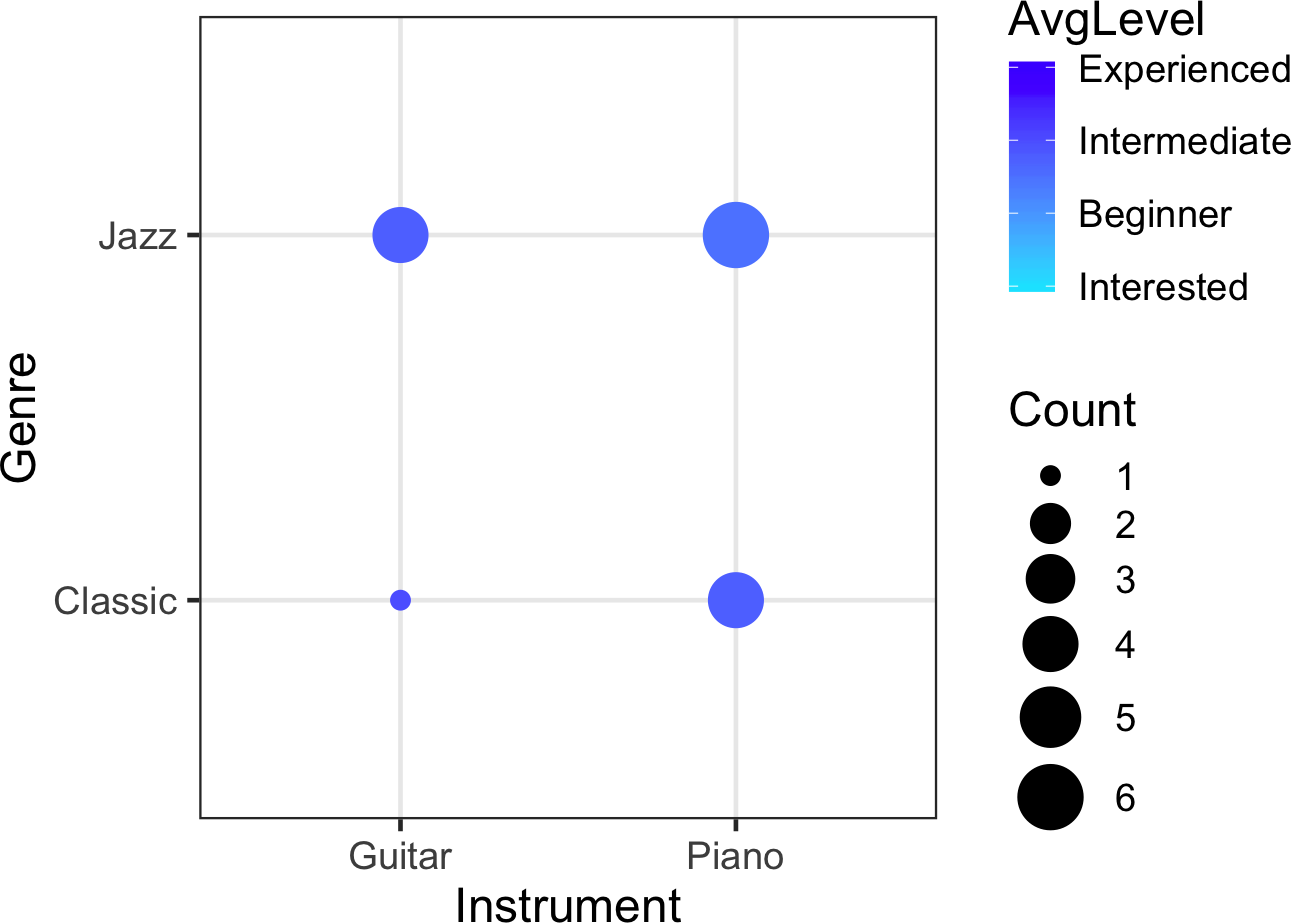
ggBubbles v0.1.4: Implements mini bubble plots to display more information for discrete data than traditional bubble plots do. The vignette provides examples.
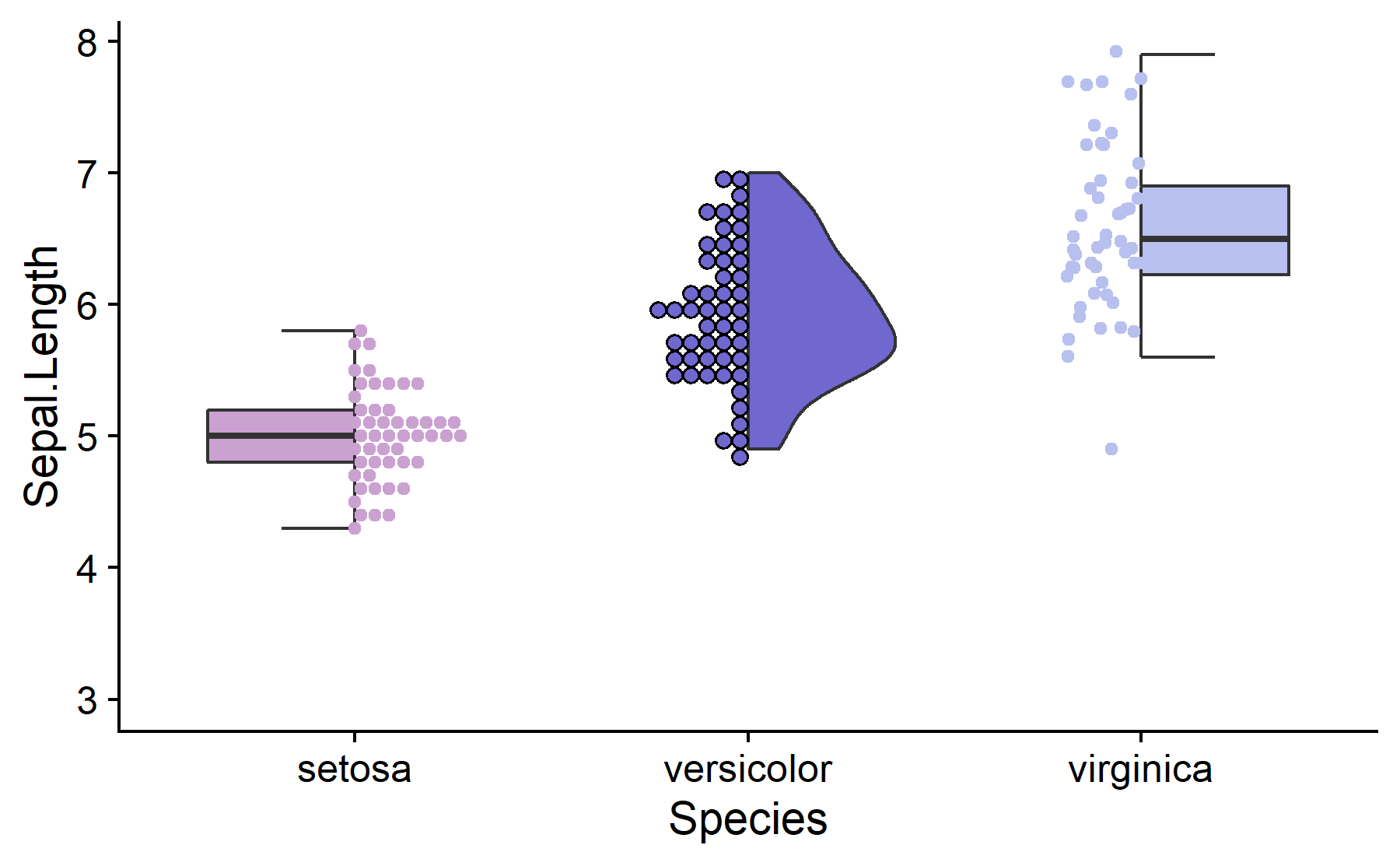
gghalves v0.0.1: Implements a ggplot2 extension for easy plotting of half-half geom combinations: think half boxplot and half jitterplot, or half violinplot and half dotplot.
You may leave a comment below or discuss the post in the forum community.rstudio.com.