Nicolas Nguyen works in the Supply Chain industry, in the area of Demand and Supply Planning, S&OP and Analytics, where he enjoys developing solutions using R and Shiny. Outside his job, he teaches data visualization in R at the Engineering School EIGSI and Business School Excelia in the city of La Rochelle, France.
Introduction
Demand & Supply Planning requires forecasting techniques to determine the inventory needed to fulfill future orders. We can build end-to-end supply chain monitoring processes with R to identify potential issues and run scenario testing.
In a 3-part series, I will walk through a Demand & Supply Planning workflow.
- In October, we published the first post, Using R for Projected Inventory Calculations in Demand & Supply Planning. It is an introduction to projected inventory and coverage methodology. Check it out if you haven’t read it yet!
- This post, Analyzing Projected Calculations Using R, presents an analysis of a demo dataset using the planr package.
- The final post, Visualizing Projected Calculations with reactable and Shiny, will answer the question: how would you present your results to your boss once the analysis is done?
By the end of the series, you will understand how and why to use R for Demand & Supply Planning calculations. Let’s continue!
The “problem” we aim to solve
In Demand & Supply Planning, we often need to calculate projected inventories (inventory needed to fulfill future orders) and projected coverages (demand needed to cover periods of time). In my previous post, we discussed the methodology behind these calculations. If you haven’t read it, click here!
This post will focus on analyzing a demo dataset using the proj_inv() function from the planr package. This function calculates projected inventories and coverages with also some analysis features. Then, we can apply the projected inventories & coverages methodology to analyze our data using R!
Demand & Supply Planning datasets
A typical Demand & Supply Planning dataset has the following basic elements, which are essential to calculate projected inventories & coverages:
- An Item (a SKU or a DFU) or a reference (a group/family of SKUs for example)
- A Period
- An Opening Inventories
- Then a Demand and a Supply Plan
We can also add more features, such as stocks parameters expressed in units, coverages, or a combination of both (for example, ensuring a minimum of one month coverage, and also at least two units of stocks).
Overview of the demo dataset
To illustrate a typical Demand & Supply Planning dataset, we can use the demo dataset, [Blueprint_DB]. This dataset contains dummy data that displays common situations in Demand and Supply Planning (alerts, shortages, overstocks, etc.). [Blueprint_DB] also contains data for the most common type of coverage, minimum and maximum targets.
We can upload the dataset directly from the planr package:
library(tidyr)
library(dplyr)
library(stringr)
library(lubridate)##
## Attaching package: 'lubridate'## The following objects are masked from 'package:base':
##
## date, intersect, setdiff, unionlibrary(planr)
library(ggplot2)
Blueprint_DB <- planr::blueprintglimpse(Blueprint_DB)## Rows: 520
## Columns: 7
## $ DFU <chr> "Item 000001", "Item 000002", "Item 000003", "Item…
## $ Period <date> 2022-07-03, 2022-07-03, 2022-07-03, 2022-07-03, 2…
## $ Demand <dbl> 364, 1419, 265, 1296, 265, 1141, 126, 6859, 66, 38…
## $ Opening.Inventories <dbl> 6570, 5509, 2494, 7172, 1464, 9954, 2092, 17772, 1…
## $ Supply.Plan <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
## $ Min.Stocks.Coverage <dbl> 4, 4, 4, 6, 4, 6, 4, 6, 4, 4, 4, 4, 4, 6, 4, 6, 4,…
## $ Max.Stocks.Coverage <dbl> 8, 6, 12, 6, 12, 6, 8, 10, 12, 12, 8, 6, 12, 6, 12…The dataset has seven fields: Demand Forecast Unit (DFU), Period, Demand, Opening Inventories, Supply Plan, Minimum Stocks Coverage, and Maximum Stocks Coverage. We can use a reactable table to look through all the information at once. This helps us get a sense of the distribution of the data and what it looks like for each variable over time. (Code for the table below is in the Appendix.)
[Table 1: Display of [Blueprint_DB] Data by Column]
Let’s go through each of these columns.
- DFU: this is a single product (also called SKU, “Storage Keeping Unit”) with certain characteristics. For example, a SKU sold in one particular distribution channel. In this dataset, we have 10 items.
unique(Blueprint_DB$DFU)## [1] "Item 000001" "Item 000002" "Item 000003" "Item 000004" "Item 000005"
## [6] "Item 000006" "Item 000007" "Item 000008" "Item 000009" "Item 000010"- Period: the horizon of time during which we will project our inventories calculation. It could be monthly, weekly, daily (and so on) buckets, over a certain range, for example, 24 months or 52 weeks. In this case, it is a weekly bucket over 52 weeks.
range(Blueprint_DB$Period)## [1] "2022-07-03" "2023-06-25"- Demand: the Demand Forecast for each period of time, expressed in units.
- For example, this could be Sales Forecasts or Replenishment Forecasts (if we ship to one warehouse to replenish it).
Looking at the Demand, there’s a range from no demand for units to a demand of 6859 units.
summary(Blueprint_DB$Demand)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0 62 119 508 690 6859- Opening Inventories: our available stocks at the beginning of the horizon, expressed in units.
The first date in our Period is 2022-07-03. Let’s take a look at the summary statistics, where we can see the range of opening inventory from 1222 to 17,772 units:
July_03 <- Blueprint_DB %>% filter(Period == "2022-07-03")
summary(July_03$Opening.Inventories)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1222 2192 4460 5766 7022 17772- Supply Plan: the quantities that we will receive to replenish our stocks at a given time, expressed in units.
The replenishment amount in the Supply Plan ranges from no replenishment to replenishment of over 16,000 units.
summary(Blueprint_DB$Supply.Plan)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0 0 0 256 0 16104- Minimum Stocks Coverage: a parameter of minimum stocks expressed in the number of periods of coverage.
- For example, if we put two months, we aim to maintain a minimum stock coverage of two months, based on the Demand Forecasts.
- Maximum Stocks Coverage: a parameter of maximum stocks expressed in the number of coverage periods.
- If we put six months, it means that we aim to maintain our stocks below the coverage of six months, based on the Demand Forecasts.
Some items, like “Item 000004” have the same min and max stocks coverage throughout the period. Other items, like “Item 000009” have variable min and max stocks coverage over time.
It’s always helpful to look at a specific item to better understand the data. We want to ensure it contains all the information that we need:
- Dimensions: [DFU] and [Period]
- Demand and Supply Planning Values: [Demand] / [Opening Inventories] / [Supply Plan]
- (Target) Stocks Levels: [Min.Stocks.Coverage] and [Max.Stocks.Coverage]
For example, let’s look closer at “Item 000008” and verify all the information is there:
Item_000008 <- filter(Blueprint_DB, Blueprint_DB$DFU == "Item 000008")
summary(Item_000008)## DFU Period Demand Opening.Inventories
## Length:52 Min. :2022-07-03 Min. : 500 Min. : 0
## Class :character 1st Qu.:2022-09-30 1st Qu.: 744 1st Qu.: 0
## Mode :character Median :2022-12-28 Median :1176 Median : 0
## Mean :2022-12-28 Mean :2203 Mean : 342
## 3rd Qu.:2023-03-27 3rd Qu.:3432 3rd Qu.: 0
## Max. :2023-06-25 Max. :6859 Max. :17772
## Supply.Plan Min.Stocks.Coverage Max.Stocks.Coverage
## Min. : 0 Min. :6 Min. :10
## 1st Qu.: 0 1st Qu.:6 1st Qu.:10
## Median : 0 Median :6 Median :10
## Mean : 989 Mean :6 Mean :10
## 3rd Qu.: 0 3rd Qu.:6 3rd Qu.:10
## Max. :16104 Max. :6 Max. :10Looking at our summary statistics, we see:
- Our [DFU] is “Item 000008”.
- We have a [Period] of 52 weeks from 2022-07-03 until 2023-07-03.
- The [Opening Inventory] is 17,772 units.
- [Demand] ranges from 500 to 6859 units, with an average of 2203 units.
- [Supply] ranges from 0 to 16,104 units, with an average of 989 units.
- In this case, the [Min.Stocks.Coverage] coverage is constant at 6 units, and the [Max.Stocks.Coverage] is constant at 10.
Great, we have what we need!
This was an overview of a standard, complete, and tidy database, ready to be used for a Demand & Supply planning calculation. All the needed elements are there, organized in three groups of data: Dimensions / Demand & Supply Planning Values / Stocks Levels. Now, we can move on to our calculations!
Calculation of the Projected Inventories
We are going to calculate two things, applying the methodology we saw previously (read about it in the previous post of the series):
- Projected Inventories
- Definition: [Stocks at the beginning of a Period of time] - [Demand of the Period] + [Supply Plan to be received during this Period]
- At the very beginning: [Stocks at the beginning of a Period of time] = [Opening Inventories]
- Related Projected Coverages
- Definition: how many periods of Demand (forecasts) do the Projected Inventories of a Period of time cover
Using R means that the analysis can be simple and fast. It provides us with a summary view of the portfolio, and then we can zoom in on the items with risks of shortages or overstocks.
Run proj_inv()
To see how simple and fast it can be to calculate projected inventories and coverages, let’s apply the function proj_inv() from the planr package to the whole demo dataset to create this summary view:
# Create a calculated database for the Projected Inventories @ DFU level
Calculated_DB <- proj_inv(
data = Blueprint_DB,
DFU = DFU,
Period = Period,
Demand = Demand,
Opening.Inventories = Opening.Inventories,
Supply.Plan = Supply.Plan,
Min.Stocks.Coverage = Min.Stocks.Coverage,
Max.Stocks.Coverage = Max.Stocks.Coverage
)Let’s have a look at the output’s column headers:
colnames(Calculated_DB)## [1] "DFU" "Period"
## [3] "Demand" "Opening.Inventories"
## [5] "Calculated.Coverage.in.Periods" "Projected.Inventories.Qty"
## [7] "Supply.Plan" "Min.Stocks.Coverage"
## [9] "Max.Stocks.Coverage" "Safety.Stocks"
## [11] "Maximum.Stocks" "PI.Index"
## [13] "Ratio.PI.vs.min" "Ratio.PI.vs.Max"After the calculation using proj_inv(), we have new columns that give us a complete database for automated analysis.
- 1st group: Calculated Columns
Projected.Inventories.Qty: Calculation of projected inventoriesCalculated.Coverage.in.Periods: Calculation of coverages in number of periodsSafety.StocksandMaximum.Stocks: Projected Stocks Targets (minimum & maximum) in units, useful for further analysis
- 2nd group: Analysis Features
- To automate screening and facilitate the decision taking process:
PI.Index: Projected Inventories Index: basically, how the [projected inventories] are doing (OK, alert, shortage, overstocks)Ratio.PI.vs.min: A ratio [Projected Inventories] vs. [Minimum Stocks Target]: used with a threshold filter, it allows us to identify the relevant SKUs quicklyRatio.PI.vs.Max: A ratio [Projected Inventories] vs. [Maximum Stocks Target], same as above
- To automate screening and facilitate the decision taking process:
Once we have run proj_inv(), we can automate the screening of our demand & supply. We can quickly know if we need to change our inventories and how to do so. This is very powerful as it means we can easily adjust based on Demand & Supply.
Results from proj_inv()
Let’s revisit “Item 000008” using this new dataset with calculated columns using the reactable package:
Table 2: The results after applying the proj_inv() function.
The new columns in yellow, green, and blue colors have been calculated and added to the original database. We can quickly scan through “Item 000008” for any particular period and notice information such as:
- The calculated coverage on 2022-07-03 is 1.6 (based on Upcoming Demand, we expect our inventory to last 1.6 weeks). The next week, it is 0.6.
- From 2022-07-03 to 2022-09-11, we should be on Alert that we will fall below our minimum stock inventory. On 2022-09-18, we fall into shortage.
We can find specific numbers for each Period by scrolling through the table. That is just from proj_inv(), without having to do any manual calculations or corrections.
Outside the analysis features, proj_inv() is very fast. Below are calculations of the speed on a Windows 10 x64 release. If we manage a portfolio of 200 SKUs over a 52 weeks horizon (weekly bucket), the calculation and analysis are done in only 5 seconds. The calculation is still pretty fast, up to 500 SKUs, which makes it quite handy if we want to run some simulations straight in Shiny.
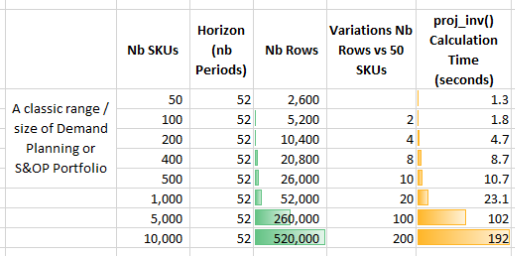
Chart of a classic range and size of Demand Planning or S&OP Portfolio
When we work on the S&OP (Sales & Operations Planning) Process, we work at an aggregated level (production families of products) and in monthly buckets. There are limited numbers of items and the horizon is typically 24 months. We can use the proj_inv() function to quickly calculate and analyze the projected inventories & coverages through a (sometimes complex) supply chain network at the same time.
Learn more
Thank you for reading this walkthrough of applying proj_inv() on a Demand & Supply Planning dataset! I hope you see what is needed to run projected inventory calculations, and how a single function in R can provide important information on projected inventories and coverages.
The reactable package makes quick, easy, pretty tables that are easy to sort and scan. What if we want to show more visual information, like color highlighting and charts?
…let’s find out in the next blog post..!
In the meantime, here are some useful links:
- Previous post: Using R for Projected Inventory Calculations in Demand & Supply Planning
- planr package GitHub repository: https://github.com/nguyennico/planr
- URL for a Shiny app showing a demo of the
proj_inv()andlight_proj_inv()functions: Demo: app proj_inv() function (shinyapps.io)
Appendix
Code for the reactable table summarising Blueprint_DB:
library(sparkline)
#-------------------
# Create Value_DB
#-------------------
# aggregation
tab_scan <- blueprint %>% select(DFU, Demand, Opening.Inventories, Supply.Plan,
Min.Stocks.Coverage,
Max.Stocks.Coverage) %>%
group_by(DFU) %>%
summarise(Total.Demand = sum(Demand),
Opening.Inventories = sum(Opening.Inventories),
Supply.Plan = sum(Supply.Plan),
Min.Stocks.Coverage = mean(Min.Stocks.Coverage),
Max.Stocks.Coverage = mean(Max.Stocks.Coverage)
)
# Get results
Value_DB <- tab_scan
#-------------------
# Create Sparklines for Demand
#-------------------
# replace missing values by zero
blueprint$Demand[is.na(blueprint$Demand)] <- 0
# aggregate
tab_scan <- blueprint %>%
group_by(DFU,
Period) %>%
summarise(Quantity = sum(Demand))
# generate Sparkline
Sparkline_Demand_DB <- tab_scan %>%
group_by(DFU) %>%
summarise(Demand.Quantity = list(Quantity))
#-------------------
# Create Sparklines for Supply Plan
#-------------------
# replace missing values by zero
blueprint$Supply.Plan[is.na(blueprint$Supply.Plan)] <- 0
# aggregate
tab_scan <- blueprint %>%
group_by(DFU,
Period) %>%
summarise(Quantity = sum(Supply.Plan))
# generate Sparkline
Sparkline_Supply_DB <- tab_scan %>%
group_by(DFU) %>%
summarise(Supply.Quantity = list(Quantity))
#----------------------------------------
# Link both databases
tab_scan <- left_join(Value_DB, Sparkline_Demand_DB)
tab_scan <- left_join(tab_scan, Sparkline_Supply_DB)
# Get Results
Overview_DB <- tab_scan
reactable(
tab_scan,
compact = TRUE,
defaultSortOrder = "asc",
defaultSorted = c("DFU"),
defaultPageSize = 20,
columns = list(
`DFU` = colDef(name = "Item", minWidth = 150),
`Opening.Inventories` = colDef(
name = "Opening Inventories (units)",
aggregate = "sum",
footer = function(values)
formatC(
sum(values),
format = "f",
big.mark = ",",
digits = 0
),
format = colFormat(separators = TRUE, digits = 0)
#style = list(background = "yellow",fontWeight = "bold")
),
`Total.Demand` = colDef(
name = "Total Demand (units)",
aggregate = "sum",
footer = function(values)
formatC(
sum(values),
format = "f",
big.mark = ",",
digits = 0
),
format = colFormat(separators = TRUE, digits = 0),
style = list(background = "yellow", fontWeight = "bold")
),
`Supply.Plan` = colDef(
name = "Supply Plan (units)",
aggregate = "sum",
footer = function(values)
formatC(
sum(values),
format = "f",
big.mark = ",",
digits = 0
),
format = colFormat(separators = TRUE, digits = 0)
),
`Min.Stocks.Coverage` = colDef(
name = "Min Stocks Coverage (periods)",
cell = data_bars(tab_scan,
#round_edges = TRUE
#value <- format(value, big.mark = ","),
#number_fmt = big.mark = ",",
fill_color = "#32CD32",
#fill_opacity = 0.8,
text_position = "outside-end")
),
`Max.Stocks.Coverage` = colDef(
name = "Max Stocks Coverage (periods)",
cell = data_bars(tab_scan,
#round_edges = TRUE
#value <- format(value, big.mark = ","),
#number_fmt = big.mark = ",",
fill_color = "#FFA500",
#fill_opacity = 0.8,
text_position = "outside-end")
),
Demand.Quantity = colDef(
name = "Demand",
cell = function(value, index) {
sparkline(tab_scan$Demand.Quantity[[index]])
}
),
Supply.Quantity = colDef(
name = "Supply",
cell = function(values) {
sparkline(values, type = "bar")
}
)
),
# close columns list
defaultColDef = colDef(footerStyle = list(fontWeight = "bold")),
columnGroups = list(
colGroup(
name = "Demand & Supply Inputs",
columns = c("Total.Demand", "Opening.Inventories", "Supply.Plan")
),
colGroup(
name = "Stocks Targets Parameters",
columns = c("Min.Stocks.Coverage", "Max.Stocks.Coverage")
)
)
) # close reactable
You may leave a comment below or discuss the post in the forum community.rstudio.com.